- 2021-06-30 发布 |
- 37.5 KB |
- 48页


申明敬告: 本站不保证该用户上传的文档完整性,不预览、不比对内容而直接下载产生的反悔问题本站不予受理。
文档介绍
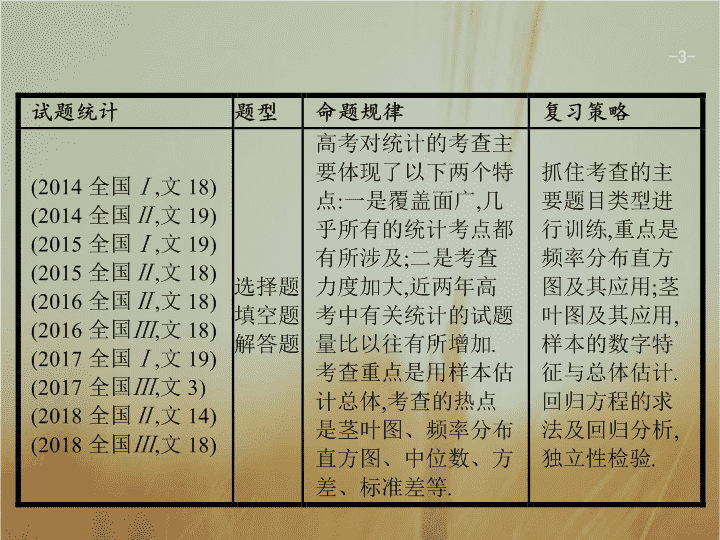
2019届二轮复习统计与统计案例课件(48张)(全国通用)
专题七 概率统计 7.1 统计与统计案例 - 3 - - 4 - 命题热点一 命题热点二 命题热点三 命题热点四 频率分布直方图的应用 【思考】 观察频率分布直方图能得到哪些信息? 例 1 某公司为了解用户对其产品的满意度,从A,B两地区分别随机调查了40个用户,根据用户对产品的满意度评分,得到A地区用户满意度评分的频率分布直方图和B地区用户满意度评分的频数分布表 . A 地区用户满意度评分的频率分布直方图 - 5 - 命题热点一 命题热点二 命题热点三 命题热点四 B 地区用户满意度评分的频数分布表 - 6 - 命题热点一 命题热点二 命题热点三 命题热点四 (1)作出B地区用户满意度评分的频率分布直方图,并通过直方图比较两地区满意度评分的平均值及分散程度(不要求计算出具体值,给出结论即可); B 地区用户满意度评分的频率分布直方图 - 7 - 命题热点一 命题热点二 命题热点三 命题热点四 (2) 根据用户满意度评分 , 将用户的满意度分为三个等级 : 估计哪个地区用户的满意度等级为不满意的概率大 ? 说明理由 . - 8 - 命题热点一 命题热点二 命题热点三 命题热点四 解 (1) B 地区用户满意度评分的频率分布直方图 通过两地区用户满意度评分的频率分布直方图可以看出 ,B 地区用户满意度评分的平均值高于 A 地区用户满意度评分的平均值 ;B 地区用户满意度评分比较集中 , 而 A 地区用户满意度评分比较分散 . - 9 - 命题热点一 命题热点二 命题热点三 命题热点四 (2)A 地区用户的满意度等级为不满意的概率大 . 记 C A 表示事件 :“A 地区用户的满意度等级为不满意 ”; C B 表示事件 :“B 地区用户的满意度等级为不满意 ” . 由直方图得 P ( C A ) 的估计值为 (0 . 01 + 0 . 02 + 0 . 03) × 10 = 0 . 6, P ( C B ) 的估计值为 (0 . 005 + 0 . 02) × 10 = 0 . 25 . 所以 A 地区用户的满意度等级为不满意的概率大 . - 10 - 命题热点一 命题热点二 命题热点三 命题热点四 - 11 - 命题热点一 命题热点二 命题热点三 命题热点四 对点训练 1 某大学艺术专业 400 名学生参加某次测评 , 根据男女学生人数比例 , 使用分层抽样的方法从中随机抽取了 100 名学生 , 记录他们的分数 , 将数据分成 7 组 :[20,30),[30,40), … ,[80,90], 并整理得到如下频率分布直方图 : - 12 - 命题热点一 命题热点二 命题热点三 命题热点四 (1) 从总体的 400 名学生中随机抽取一人 , 估计其分数小于 70 的概率 ; (2) 已知样本中分数小于 40 的学生有 5 人 , 试估计总体中分数在区间 [40,50) 内的人数 ; (3) 已知样本中有一半男生的分数不小于 70, 且样本中分数不小于 70 的男女生人数相等 . 试估计总体中男生和女生人数的比例 . 解 (1) 根据频率分布直方图可知 , 样本中分数不小于 70 的频率为 (0 . 02 + 0 . 04) × 10 = 0 . 6, 所以样本中分数小于 70 的频率为 1 - 0 . 6 = 0 . 4 . 所以从总体的 400 名学生中随机抽取一人 , 其分数小于 70 的概率估计为 0 . 4 . - 13 - 命题热点一 命题热点二 命题热点三 命题热点四 (2) 根据题意 , 样本中分数不小于 50 的频率为 (0 . 01 + 0 . 02 + 0 . 04 + 0 . 02) × 10 = 0 . 9, 分数在区间 [40,50) 内的人数为 100 - 100 × 0 . 9 - 5 = 5 . 所以总体中分数在区间 [40,50) 内的人数估计为 400 × = 20 . (3) 由题意可知 , 样本中分数不小于 70 的学生人数为 (0 . 02 + 0 . 04) × 10 × 100 = 60, 所以样本中分数不小于 70 的男生人数为 60 × = 30 . 所以样本中的男生人数为 30 × 2 = 60, 女生人数为 100 - 60 = 40, 男生和女生人数的比例为 60 ∶ 40 = 3 ∶ 2 . 所以根据分层抽样原理 , 总体中男生和女生人数的比例估计为 3 ∶ 2 . - 14 - 命题热点一 命题热点二 命题热点三 命题热点四 用样本的数字特征估计总体 【思考 1 】 样本有哪些数字特征?这些数字特征反映了样本数据的什么情况? 【思考 2 】 茎叶图刻画数据有哪些优点及不足? - 15 - 命题热点一 命题热点二 命题热点三 命题热点四 例 2 为比较甲、乙两地某月14时的气温状况,随机选取该月中的5天,将这5天中14时的气温数据(单位: ℃ )制成如图所示的茎叶图 . 考虑以下结论: ① 甲地该月14时的平均气温低于乙地该月14时的平均气温; ② 甲地该月14时的平均气温高于乙地该月14时的平均气温; ③ 甲地该月14时的气温的标准差小于乙地该月14时的气温的标准差; ④ 甲地该月14时的气温的标准差大于乙地该月14时的气温的标准差 . 其中根据茎叶图能得到的统计结论的编号为( ) A. ①③ B. ①④ C. ②③ D. ②④ 答案 解析 解析 关闭 答案 解析 关闭 - 16 - 命题热点一 命题热点二 命题热点三 命题热点四 题后反思 1 . 样本的数字特征主要有 : 中位数、众数、平均数、标准差、方差 , 中位数、平均数、众数反映了这组数据的集中程度 , 反映了样本数据的总体水平 ; 而标准差、方差反映这组数据的波动情况 , 标准差或方差越大 , 波动越大 . 2 . 茎叶图刻画数据的优点 :(1) 所有数据信息都可由茎叶图看到 ;(2) 茎叶图便于记录和表示 , 能反映数据在各段上的分布情况 . 3 . 茎叶图刻画数据的不足 : 茎叶图不能直接反映总体的分布情况 , 这就需要通过茎叶图给出的数据求出数据的数字特征 , 进一步估计总体情况 . - 17 - 命题热点一 命题热点二 命题热点三 命题热点四 对点训练 2 某市为了考核甲、乙两部门的工作情况,随机访问了50名市民 . 根据这50名市民对这两部门的评分(评分越高表明市民的评价越高),绘制茎叶图如下: (1)分别估计该市的市民对甲、乙两部门评分的中位数; (2)分别估计该市的市民对甲、乙两部门的评分高于90的概率; (3)根据茎叶图分析该市的市民对甲、乙两部门的评价 . - 18 - 命题热点一 命题热点二 命题热点三 命题热点四 解 (1) 由所给茎叶图知 ,50 名市民对甲部门的评分由小到大排序 , 排在第 25,26 名的是 75,75, 则样本中位数为 75, 所以该市的市民对甲部门评分的中位数的估计值是 75 . 50 名市民对乙部门的评分由小到大排序 , 排在第 25,26 名的是 66,68, 则样本中位数为 , 所以该市的市民对乙部门评分的中位数的估计值是 67 . (2) 由所给茎叶图知 ,50 名市民对甲、乙部门的评分高于 90 的比率分别为 , 故该市的市民对甲、乙部门的评分高于 90 的概率的估计值分别为 0 . 1,0 . 16 . - 19 - 命题热点一 命题热点二 命题热点三 命题热点四 (3) 由所给茎叶图知 , 市民对甲部门的评分的中位数高于对乙部门的评分的中位数 , 而且由茎叶图可以大致看出对甲部门的评分的标准差要小于对乙部门的评分的标准差 , 说明该市市民对甲部门的评价较高、评价较为一致 , 对乙部门的评价较低 , 评价差异较大 . ( 注 : 利用其他统计量进行分析 , 结论合理的也可 ) - 20 - 命题热点一 命题热点二 命题热点三 命题热点四 回归方程的求法及回归分析 【思考】 两个变量具备什么关系才能用线性回归方程来预测?如何判断两个变量具有这种关系? 例 3 某公司为确定下一年度投入某种产品的宣传费,需了解年宣传费 x (单位:千元)对年销售量 y (单位:t)和年利润 z (单位:千元)的影响 . 对近8年的年宣传费 x i 和年销售量 y i ( i= 1,2, … ,8)数据作了初步处理,得到下面的散点图及一些统计量的值 . - 21 - 命题热点一 命题热点二 命题热点三 命题热点四 - 22 - 命题热点一 命题热点二 命题热点三 命题热点四 (1) 根据散点图判断 , y=a+bx 与 y=c+d 哪一个适宜作为年销售量 y 关于年宣传费 x 的回归方程类型 ?( 给出判断即可 , 不必说明理由 ) (2) 根据 (1) 的判断结果及表中数据 , 建立 y 关于 x 的回归方程 ; (3) 已知这种产品的年利润 z 与 x , y 的关系为 z= 0 . 2 y-x. 根据 (2) 的结果回答下列问题 : ① 当年宣传费 x= 49 时 , 年销售量及年利润的预报值是多少 ? ② 当年宣传费 x 为何值时 , 年利润的预报值最大 ? - 23 - 命题热点一 命题热点二 命题热点三 命题热点四 - 24 - 命题热点一 命题热点二 命题热点三 命题热点四 - 25 - 命题热点一 命题热点二 命题热点三 命题热点四 题后反思 当两个变量之间具有相关关系时 , 才可通过线性回归方程来估计和预测 . 对两个变量的相关关系的判断有两个方法 : 一是根据散点图 , 具有很强的直观性 , 直接得出两个变量是正相关或负相关 ; 二是计算相关系数法 , 这种方法能比较准确地反映相关程度 , 相关系数的绝对值越接近 1, 相关性就越强 . - 26 - 命题热点一 命题热点二 命题热点三 命题热点四 对点训练 3 (2018 全国 Ⅱ , 文 18) 下图是某地区 2000 年至 2016 年环境基础设施投资额 y ( 单位 : 亿元 ) 的折线图 . - 27 - 命题热点一 命题热点二 命题热点三 命题热点四 为了预测该地区 2018 年的环境基础设施投资额 , 建立了 y 与时间变量 t 的两个线性回归模型 . 根据 2000 年至 2016 年的数据 ( 时间变量 t 的值依次为 1,2, … ,17) 建立模型 ① : =- 30 . 4 + 13 . 5 t ; 根据 2010 年至 2016 年的数据 ( 时间变量 t 的值依次为 1,2, … ,7) 建立模型 ② : = 99 + 17 . 5 t. (1) 分别利用这两个模型 , 求该地区 2018 年的环境基础设施投资额的预测值 ; (2) 你认为用哪个模型得到的预测值更可靠 ? 并说明理由 . 解 (1) 利用模型 ① , 该地区 2018 年的环境基础设施投资额的预测值为 =- 30 . 4 + 13 . 5 × 19 = 226 . 1(亿元) . 利用模型 ② ,该地区2018年的环境基础设施投资额的预测值为 = 99 + 17 . 5 × 9 = 256 . 5(亿元) . - 28 - 命题热点一 命题热点二 命题热点三 命题热点四 (2) 利用模型 ② 得到的预测值更可靠 . 理由如下 : (i) 从折线图可以看出 ,2000 年至 2016 年的数据对应的点没有随机散布在直线 y=- 30 . 4 + 13 . 5 t 上下 , 这说明利用 2000 年至 2016 年的数据建立的线性模型 ① 不能很好地描述环境基础设施投资额的变化趋势 . 2010 年相对 2009 年的环境基础设施投资额有明显增加 ,2010 年至 2016 年的数据对应的点位于一条直线的附近 , 这说明从 2010 年开始环境基础设施投资额的变化规律呈线性增长趋势 , 利用 2010 年至 2016 年的数据建立的线性模型 = 99 + 17 . 5 t 可以较好地描述 2010 年以后的环境基础设施投资额的变化趋势 , 因此利用模型 ② 得到的预测值更可靠 . - 29 - 命题热点一 命题热点二 命题热点三 命题热点四 (ii) 从计算结果看 , 相对于 2016 年的环境基础设施投资额 220 亿元 , 由模型 ① 得到的预测值 226 . 1 亿元的增幅明显偏低 , 而利用模型 ② 得到的预测值的增幅比较合理 , 说明利用模型 ② 得到的预测值更可靠 . ( 以上给出了 2 种理由 , 答出其中任意一种或其他合理理由均可得分 ) - 30 - 命题热点一 命题热点二 命题热点三 命题热点四 独立性检验 【思考】 独立性检验有什么用途? 例 4 某高校共有学生15 000名,其中男生10 500名,女生4 500名 . 为调查该校学生每周平均体育运动时间的情况,采用分层抽样的方法,收集300名学生每周平均体育运动时间的样本数据(单位:h) . - 31 - 命题热点一 命题热点二 命题热点三 命题热点四 (1) 应收集多少名女生的样本数据 ? (2) 根据这 300 个样本数据 , 得到学生每周平均体育运动时间的频率分布直方图 ( 如图 ), 其中样本数据的分组区间为 :[0,2],(2,4],(4,6],(6,8],(8,10],(10,12] . 估计该校学生每周平均体育运动时间超过 4 h 的概率 ; - 32 - 命题热点一 命题热点二 命题热点三 命题热点四 (3) 在样本数据中 , 有 60 名女生的每周平均体育运动时间超过 4 h, 请完成每周平均体育运动时间与性别列联表 , 能否在犯错误的概率不超过 0 . 05 的前提下认为该校学生每周平均体育运动时间与性别有关系 ? - 33 - 命题热点一 命题热点二 命题热点三 命题热点四 解 (1)300 × = 90, 所以应收集 90 名女生的样本数据 . (2) 由频率分布直方图得 1 - 2 × (0 . 100 + 0 . 025) = 0 . 75, 所以该校学生每周平均体育运动时间超过 4 h 的概率的估计值为 0 . 75 . (3) 由 (2) 知 ,300 × 0 . 75 = 225( 人 ), 则有 225 人每周平均体育运动时间超过 4 h,75 人每周平均体育运动时间不超过 4 h . 因为样本数据中有 210 份是关于男生的 ,90 份是关于女生的 , 所以每周平均体育运动时间与性别列联表如下 : 每周平均体育运动时间与性别列联表 - 34 - 命题热点一 命题热点二 命题热点三 命题热点四 结合列联表可算得 所以 , 能在犯错误的概率不超过 0 . 05 的前提下认为该校学生的每周平均体育运动时间与性别有关系 . - 35 - 命题热点一 命题热点二 命题热点三 命题热点四 题后反思 利用独立性检验 , 能够帮助我们对日常生活中的实际问题作出合理的推断和预测 . 独立性检验就是考察两个分类变量是否有关系 , 并能较为准确地给出这种判断的可信度 , 具体做法是根据公式 计算随机变量的观测值 k , k 值越大 , 说明 “ 两个变量有关系 ” 的可能性越大 . - 36 - 命题热点一 命题热点二 命题热点三 命题热点四 对点训练 4 海水养殖场进行某水产品的新、旧网箱养殖方法的产量对比 , 收获时各随机抽取了 100 个网箱 , 测量各箱水产品的产量 ( 单位 :kg), 其频率分布直方图如下 : 旧养殖法 - 37 - 命题热点一 命题热点二 命题热点三 命题热点四 新养殖法 - 38 - 命题热点一 命题热点二 命题热点三 命题热点四 (1) 记 A 表示事件 “ 旧养殖法的箱产量低于 50 kg”, 估计 A 的概率 ; (2) 填写下面列联表 , 并根据列联表判断是否有 99% 的把握认为箱产量与养殖方法有关 ; (3) 根据箱产量的频率分布直方图 , 对这两种养殖方法的优劣进行比较 . 附 : , - 39 - 命题热点一 命题热点二 命题热点三 命题热点四 解 (1) 旧养殖法的箱产量低于 50 kg 的频率为 (0 . 012 + 0 . 014 + 0 . 024 + 0 . 034 + 0 . 040) × 5 = 0 . 62 . 因此 , 事件 A 的概率估计值为 0 . 62 . (2) 根据箱产量的频率分布直方图得列联表 由于 15 . 705 > 6 . 635, 故有 99% 的把握认为箱产量与养殖方法有关 . - 40 - 命题热点一 命题热点二 命题热点三 命题热点四 (3) 箱产量的频率分布直方图表明 : 新养殖法的箱产量平均值 ( 或中位数 ) 在 50 kg 到 55 kg 之间 , 旧养殖法的箱产量平均值 ( 或中位数 ) 在 45 kg 到 50 kg 之间 , 且新养殖法的箱产量分布集中程度较旧养殖法的箱产量分布集中程度高 , 因此 , 可以认为新养殖法的箱产量较高且稳定 , 从而新养殖法优于旧养殖法 . - 41 - 规律总结 拓展演练 1 . 对于频率分布表和频率分布直方图 , 在计数和计算时一定要准确 , 在绘制小长方形时 , 宽窄要一致 . 通过频率分布表和频率分布直方图可以对总体作出估计 . 2 . 茎叶图、频率分布表和频率分布直方图都是用来描述样本数据的分布情况的 . 茎叶图由所有样本数据构成 , 没有损失任何样本信息 , 可以随时记录 ; 而频率分布表和频率分布直方图则损失了样本的一些信息 , 必须在完成抽样后才能制作 . 3 . 若 x 1 , x 2 , … , x n 的平均数为 , 方差为 s 2 , 则 ax 1 +b , ax 2 +b , … , ax n +b 的平均数为 , 方差为 a 2 s 2 . - 42 - 规律总结 拓展演练 4 . 利用频率分布直方图求众数、中位数与平均数时 , 应注意这三者的区分 :(1) 最高的长方形的中点即众数 ;(2) 中位数左边和右边的直方图的面积是相等的 ;(3) 平均数是频率分布直方图的 “ 重心 ”, 等于频率分布直方图中每个小长方形的面积乘小长方形底边中点的横坐标之和 . 5 . 回归分析是处理变量相关关系的一种数学方法 . 主要解决 :(1) 确定特定量之间是否有相关关系 , 如果有就找出它们之间贴近的数学表达式 ;(2) 根据一组观察值 , 预测变量的取值及判断变量取值的变化趋势 ;(3) 求出线性回归方程 . 6 . 根据 K 2 的值可以判断两个分类变量有关的可信程度 . - 43 - 规律总结 拓展演练 1 . 某城市为了解游客人数的变化规律 , 提高旅游服务质量 , 收集并整理了 2014 年 1 月至 2016 年 12 月期间月接待游客量 ( 单位 : 万人 ) 的数据 , 绘制了下面的折线图 . 根据该折线图 , 下列结论错误的是 ( ) A. 月接待游客量逐月增加 B. 年接待游客量逐年增加 C. 各年的月接待游客量高峰期大致在 7,8 月 D. 各年 1 月至 6 月的月接待游客量相对于 7 月至 12 月 , 波动性更小 , 变化比较平稳 答案 解析 解析 关闭 由题图可知 2014 年 8 月到 9 月的月接待游客量在减少 , 故 A 错误 . 答案 解析 关闭 A - 44 - 规律总结 拓展演练 2 . 如图所示的茎叶图记录了甲、乙两组各 5 名工人某日的产量数据 ( 单位 : 件 ) . 若这两组数据的中位数相等 , 且平均值也相等 , 则 x 和 y 的值分别为 ( ) A.3,5 B.5,5 C.3,7 D.5,7 A 解析 甲组数据为 56,62,65,70 +x ,74; 乙组数据为 59,61,67,60 +y ,78 . 若两组数据的中位数相等 , 则 65 = 60 +y , 所以 y= 5 . 又两组数据的平均值相等 , 所以 56 + 62 + 65 + 70 +x+ 74 = 59 + 61 + 67 + 65 + 78, 解得 x= 3 . - 45 - 规律总结 拓展演练 3 . 已知一组数据4 . 7,4 . 8,5 . 1,5 . 4,5 . 5,则该组数据的方差是 . 答案 0 . 1 解析 这组数据的平均数为 × (4 . 7 + 4 . 8 + 5 . 1 + 5 . 4 + 5 . 5) = 5 . 1, 方差为 × [(4 . 7 - 5 . 1) 2 + (4 . 8 - 5 . 1) 2 + (5 . 1 - 5 . 1) 2 + (5 . 4 - 5 . 1) 2 + (5 . 5 - 5 . 1) 2 ] = 0 . 1 . - 46 - 规律总结 拓展演练 4 . 某险种的基本保费为 a ( 单位 : 元 ), 继续购买该险种的投保人称为续保人 , 续保人本年度的保费与其上年度出险次数的关联如下 : 随机调查了该险种的 200 名续保人在一年内的出险情况 , 得到如下统计表 : - 47 - 规律总结 拓展演练 (1) 记 A 为事件 :“ 一续保人本年度的保费不高于基本保费 ”, 求 P ( A ) 的估计值 ; (2) 记 B 为事件 :“ 一续保人本年度的保费高于基本保费但不高于基本保费的 160%” . 求 P ( B ) 的估计值 ; (3) 求续保人本年度平均保费的估计值 . - 48 - 规律总结 拓展演练查看更多