- 2022-09-01 发布 |
- 37.5 KB |
- 16页


申明敬告: 本站不保证该用户上传的文档完整性,不预览、不比对内容而直接下载产生的反悔问题本站不予受理。
文档介绍
地质统计学复习资料
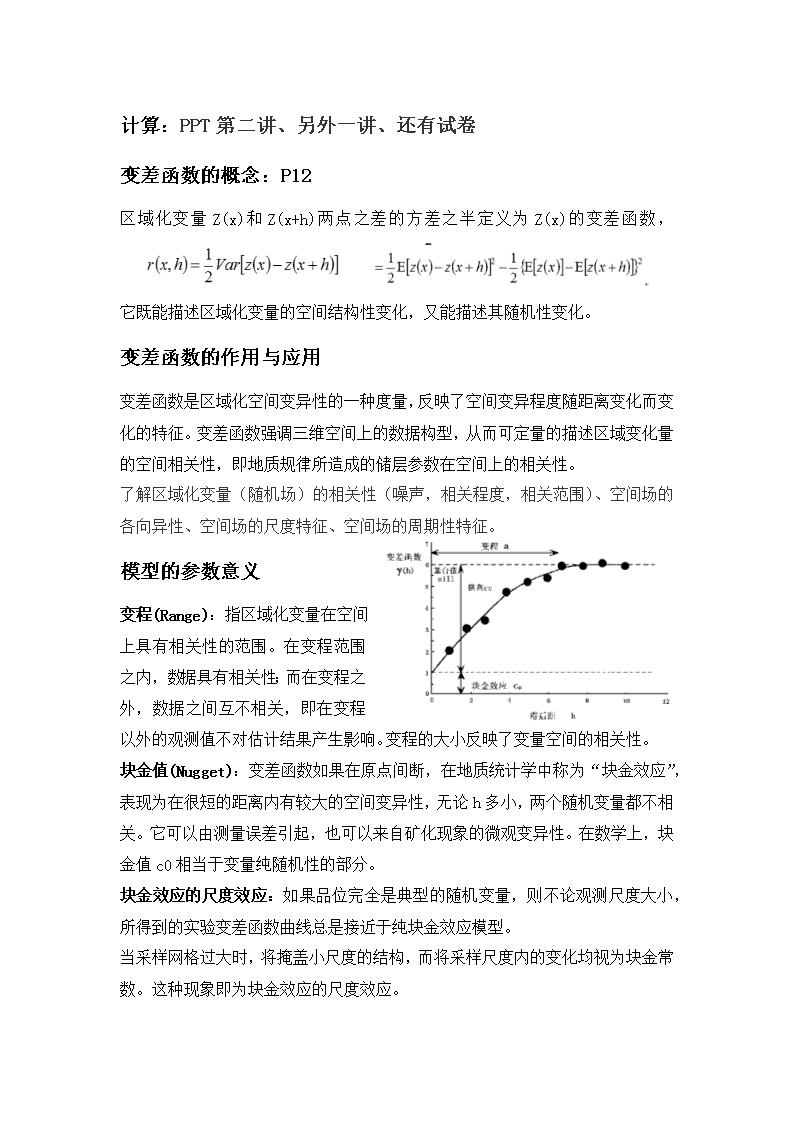
计算:PPT第二讲、另外一讲、还有试卷变差函数的概念:P12区域化变量Z(x)和Z(x+h)两点之差的方差之半定义为Z(x)的变差函数,它既能描述区域化变量的空间结构性变化,又能描述其随机性变化。变差函数的作用与应用变差函数是区域化空间变异性的一种度量,反映了空间变异程度随距离变化而变化的特征。变差函数强调三维空间上的数据构型,从而可定量的描述区域变化量的空间相关性,即地质规律所造成的储层参数在空间上的相关性。了解区域化变量(随机场)的相关性(噪声,相关程度,相关范围)、空间场的各向异性、空间场的尺度特征、空间场的周期性特征。模型的参数意义变程(Range):指区域化变量在空间上具有相关性的范围。在变程范围之内,数据具有相关性;而在变程之外,数据之间互不相关,即在变程以外的观测值不对估计结果产生影响。变程的大小反映了变量空间的相关性。块金值(Nugget):变差函数如果在原点间断,在地质统计学中称为“块金效应”,表现为在很短的距离内有较大的空间变异性,无论h多小,两个随机变量都不相关。它可以由测量误差引起,也可以来自矿化现象的微观变异性。在数学上,块金值c0相当于变量纯随机性的部分。块金效应的尺度效应:如果品位完全是典型的随机变量,则不论观测尺度大小,所得到的实验变差函数曲线总是接近于纯块金效应模型。当采样网格过大时,将掩盖小尺度的结构,而将采样尺度内的变化均视为块金常数。这种现象即为块金效应的尺度效应。\n基台值(Sill):代表变量在空间上的总变异性大小。即为变差函数在h大于变程时的值,为块金值c0和拱高cc之和。拱高:在取得有效数据的尺度上,可观测得到的变异性幅度大小。当块金值等于0时,基台值即为拱高。模型:P15为何要拟合:P14实验变差公式:PPT第2讲假设\n克里金法概念:P36克里金插值与变差函数的关系变差函数是克里金方法研究的主要工具,在克里金估计方法中,加权系数的求取是通过变差函数来获得的。由于变差函数只能反映变量的空间结构特征而不能反映变量的随机特征。所以利用克里金方法进行空间数据插差值往往可以取得理想的效果,另外通过设计变差函数,克里金方法很容易实现局部加权差值。如何理解克里金插值是最优线性无偏估计克里金插值首先考虑的是空间属性在空间位置上的变异分布.确定对一个待插点值有影响的距离范围,然后用此范围内的采样点来估计待插点的属性值。该方法在数学上可对所研究的对象提供一种最佳线性无偏估计(某点处的确定值)的方法。它是考虑了信息样品的形状、大小及与待估计块段相互间的空间位置等几何特征以及品位的空间结构之后,为达到线性、无偏和最小估计方差的估计,而对每一个样品赋与一定的系数,最后进行加权平均来估计块段品位的方法。这里的最优是指估计结果的理论方差最小,而无偏是指估计误差的期望值为零。\n最优性的判别标准克里金估计的理论方差越小,越优。与随机模拟的主要区别1、克里格插值法只考虑局部估计值的精确程度,力图对估计点的未知值作出最优的和无偏的估计,不考虑估计值的空间相关性(离散性);而随机模拟首先考虑的是结果的整体性质和模拟值的统计空间相关性,其次才是局部估计值的精度;2、插值法给出观测值间的平滑估值(如绘出研究对象的平滑曲线图),而削弱了观测数据的离散性,忽略了井间的细微变化;而条件随机模拟在插值模型中系统地加上了“随机噪音”,这样产生的结果比插值模型真实得多。“随机噪音”正是井间的细微变化,虽然对于每一个局部的点,模拟值并不完全是真实的,估计方差甚至比插值法更大,但模拟曲线能更好地表现出曲线的真实波动情况。3、插值算法(包括克里格法)只产生一个模型;而随机建模则产生多个可选的模型,各种模型之间的差别正是空间不确定性的表现。随机模拟更适于储层非均质的研究,因为随机模拟更能反映储层性质的离散性,这对油田开发生产尤为重要。应用该技术建立储层模型可以得到某一属性场的多个不同的等概率实现,用以说明该属性场的空间组合的不确定性,从而为决策者提供了更加丰富的储层模型。插值法掩盖了非均质程度(即离散性),特别是离散性明显的储层参数(如渗透率)的非均质程度,因而不适用于渗透率非均质性的表征。当然,对于一些离散性不大的储层参数,如孔隙度,应用克里格插值方法研究其空间分布,并用于估计储量,亦表现出方便、快速、准确的优越性。三维储层建模建立储层特征三维分布的数字化模型,其本质是基于三维网格表征储层特征的分布,其成果是三维数据体,本质是从三维角度对储层进行定量研究并建立其三维模型,核心是对井间储层惊醒多学科综合一体化、三维定量化及可视化的预测。模型包括有构造、属性分布和流体分布模型,建立储层模型就是油藏描述。\n序贯高斯模拟原理:P62流程图:P64范畴:P72/60优缺点:P64&以下的步骤:P62或以下序贯指示模拟原理:P73优缺点:P75/82流程图:P76\n范畴:指示模拟可用于模拟复杂各向异性的地质现象。由于各个类型变量均对应于一个指示变差函数,也就是说,对于具有不同连续性分布的类型变量(相),可给定(指定或通过数据推断)不同的指示变差函数,从而可建立各向异性的模拟图象。因此,指示模拟可用于多向分布的沉积相建模(如三角洲分流河道与河口坝复合体),也可用于断层和裂缝的随机建模。步骤:P74或以下布尔模型过程:1、把已知井位处的砂体条件优化。2、随机抽样产生预测砂体中心位置。3、是否与已知井位处的数据发生冲突,如果冲突,则须调整砂体,使之不冲突,否则进行下一步。4从经验累积概率分布函数中随机抽取该砂体的厚度。5、由已确定的厚度—宽度关系确定砂体宽度。6、计算目标函数值Fs=砂体剖面面积/剖面总面积7、重复步骤2产生的另一砂体,直至达到给定阈值为至。优点:它是储层建模方法中最简单的以中算法,很容易将沉积学的一些知识,如砂体的宽厚比,厚度分布趋势等融入到模拟结果中,主要用于勘探和开发早期阶段。缺点:完全随机的产生目标对象中心,没有考虑沉积过程中先沉积的河道砂体对后面沉积的重要控制作用,用此种方法模拟的结果往往对砂体的连通性评价过高。\n原理:布尔模拟方法是基于目标的随机模拟方法中最简单的一种方法,Matheron最早利用布尔模型用于描述岩石中颗粒与孔隙的分布。后来被用来描述储层中砂泥岩的分布[4,5]。设U为坐标随机变量,Xk是表征第k类物体几何特征(形状、大小、方向)的参数随机变量;第k类几何物体中心点的分布构成一点过程U,它可以用形状随机过程Xk和表示第k类几何物体出现与否的指标随机过程Ik两者的联合分布“示性”,从而构成一示性点过程。其中布尔方法就是依据一定的概率定律,按照空间物体分布统计规律产生这些物体中心点的空间分布,并通过2×k个随机函数Xk(u),Ik(u,k)(k=1,2,3,…,k,u∈定义域)的联合分布,确定中心点在此处的物体的几何形状、大小、属性。示性点过程原理所谓示点性过程,就是对某一空间区域内的每一个离散点进行标值的过程,其基本思路是根据点过程的概率定律,按照空间中几何物体的分布规律产生这些物体的中心点空间分布,然后将物理性质(如物理几何形状、大小、方向等)标注于每一离散点[9],可以用随机序列ψ={[xn;m(xn)]}表示,其中xn为连续空间内的一个随机点过程,m(xn)为每个点的标值从地质统计学角度讲,示点性过程就是研究目标点及其性质在三维空间中的联合分布,可定义为由表示第i类目标点在位置u处是否出现的随机函数Pi(u,i)和描述第i类目标点物理性质(几何形状、大小、方向)参数的随机变量Xi组成的集合{Pi(u,i),Xi},这样通过在空间上先确定产生目标点的位置,再模拟产生目标的相关属性,构成了一次标点过程,并得到一次模拟实现。示点性过程模拟建立在对目标体地质认识的基础上,在模拟过程中,将一些关于目标体的先验地质认识作为条件约束信息加入模型中,可以使随机模拟结果最大限度地接近地质实际。由于三维空间内目标体的分布以及目标体的属性极为复杂,在随机模拟过程中需要应用优化算法对目标体分布进行“逐步逼近”,即用各种参数分布和相互作用的多种组合进行迭代,直至最终得到一个满意的随机模拟结果为止。具体来说,就是设计一个目标函数,并确定一个目标函数阈值,根据先验地质认识随机产生目标体,计算目标函数值,直至达到目标函数阈值为止。\n优缺点:打印的文献《基于目标的随机建模方法》&根据先验地质知识、点过程理论及优化方法表征多点地质统计学的基本思路及优缺点,训练图像的来源及意义。多点地质统计学是相对于基于变差函数的两点地质统计学而言的。多点统计是利用空间多个点组合模式进行描述。其核心分为三个部分:训练图像,数据事件,多点概率,其基本思路是通过数据样板扫描训练图像建立多点统计概率,利用获得的多点统计概率进行未知节点处概率模拟。优点:在多点地质统计学中,应用“训练图像”代替变差函数表达地质变量的空间结构性,因而可克服传统地质统计学不能再现目标几何形态的不足,同时,由于该方法仍然以象元为模拟单元,而且采用序贯算法(非迭代算法),因而很容易忠实硬数据,并具有快速的特点,故克服了基于目标的随机模拟算法的不足。因此,多点地质统计学方法综合了基于象元和基于目标的算法优点,同时可克服已有的缺陷;多点统计学应用多点数据样板扫描训练图像以构建搜索树并从搜索树中求取条件概率分布函数使多点地质统计学克服了传统二点统计学难于表达复杂空间结构性和再现目标几何形态的不足。缺点:1、训练图像平稳性问题,多点统计提出了一个几何变换的方法,即通过旋转和比例压缩将非平稳训练图像变为平稳训练图像,并建立多个训练图像以获取未取样点条件概率分布函数,但是,这一方法仍是一种简单化的解决途径,可以解决具有明显趋势而且用少量定量指标如方向和压缩比例能够表达的非平稳性,而对于无规律的局部明显变异性,尚需要更为有效的解决方案。2、目标连续性问题;3、综合地震信息的问题;4、当软数据类型较多时,扫描训练图像所得的重复数太少,从而影响条件概率的推导。5、储层形态合理问题,多重网格搜索问题,6、由于多点地质统计学仍是基于相元的算法,所以只能在一定程度上重现目标的形状,对于更复杂的如尖角或U型目标的应用较差来源及意义:\n储层建模的原则我国含油气盆地类型多,储层以陆相碎屑岩及海相碳酸盐岩为主,储层成因复杂,非均质性严重。如河流、三角洲及冲积扇等环境形成的储层,在纵、横向上相变快,不同规模的非均质性严重。因此,对这类储层进行勘探与开发,将面临储层非均质性的问题。为了建立尽量符合地质实际情况的储层模型,针对我国储层的特点,制定如下建模原则。4.1 确定性建模与随机建模相结合的原则确定性建模是根据确定性资料,推测出井间确定的、惟一的储层特征分布。而随机建模是对井间未知区应用随机模拟方法建立可选的、等概率的储层地质模型。应用随机建模方法,可建立一簇等概率的储层三维模型,因而可评价储层的不确定性,进一步把握井间储层的变化。在实际建模的过程中,为了尽量降低模型中的不确定性,应尽量应用确定性信息来限定随机建模的过程,这就是随机建模与确定性建模相结合的建模思路。4.2 等时建模原则沉积地质体是在不同的时间段形成的。为了提高建模精度,在建模过程中应进行等时地质约束,即应用高分辨率层序地层学原理确定等时界面,并利用等时界面将沉积体划分为若干等时层。在建模时,按层建模,然后再将其组合为统一的三维沉积模型。同时,针对不同的等时层输入反映各自地质特征的不同的建模参数,这样可使所建模型能更客观地反映地质实际。4.3 相控储层建模原则相控建模,即首先建立沉积相、储层结构或流动单元模型,然后根据不同沉积相(砂体类型或流动单元)的储层参数定量分布规律,分相(砂体类型或流动单元)进行井间插值或随机模拟,进而建立储层参数分布模型。\n如何理解储层建模中的不确定性储层的性质本来是确定的,在每一个位置点都具有确定的性质和特征;但地下储层结构又是很复杂的,他是许多复杂地质过程(沉积作用、沉岩作用和构造作用)综合作用的结果,具有复杂的储层内部构型及储层参数的空间变化。在储层表征中,由于用于描述储层的资料总是不完备的,测井和地震有分辨率大小的问题,所得出来的结果也有误差,有很多参数本身就存在很多不确定性(测井解释和地震解释都不准确),因此人们很难掌握任一尺度下储层的确定且真实储层特征,特别是对于连续性较差且非均质性较差的陆相储层来说更加难以精确的表征储层特征。这样由于认识程度的不同,储层描述便有不确定性。储层建模的不确定性包括输入参数的不确定性和建模方法的不确定性。输入的参数不确定性包括测井解释参数的不确定性(测井过程引起的不确定性、钻井泥浆产生的不确定性、测井解释的不确定性、裂缝解释的不确定性),地震解释参数的不确定性(受地震分辨率限制,储层地震异常尺度远大于测井解释储层尺度、地震反射特征相同,其储层类型可能不一致),地质参数不确定性(野外地质露头统计参数只能给出沉积体系参数的分布范围,如何具体的去优选参数具有不确定性、局部统计的规律代替全局统计规律会产生误差),对于同一个储层,你会有不同的方法来对储层进行表征,不同的方法当然就会得到不同的表征结果,因此储层建模有不确定性。如何评价模型的好坏随机图像是否符合地质概念式;随机实现的统计参数与输入参数的接近程度;模拟现实是否忠实于真实数据,主要判别他与未参与模拟的硬数据是否吻合,如抽稀的井数据,试井反映的砂体连通性数据;模拟现实是否符合动态生产,可通过简单的二维油藏数值模拟或者局部的三维数模的“历史拟合”情况来进行判别。随机建模与不确定建模的关系所谓随机建模是指以已知的信息为基础,以随机函数为理论,应用随机模拟方法,产生可选的、等概率的储层模型方法。通过对多个等可能随机储层模型中的不确定性进行评价,以满足油田勘探开发决策在一定风险范围的正确性的需要,这是\n与确定性建模方法的重要差别。在随机建模中如果生成了大量的现实,这些现实肯定是有差别的,例如你用随机建模来计算储量,每一个现实就会得出一个计算结果,然后编制储量的累积概率分布曲线,那么在不同概率控制下,其会得到不同的结果,也就是说随机建模所得出结果是具有不确定。对储层建模的理解储层建模是近几年发展起来的高新技术,它可以实现对油气储层的定量表征及对各种尺度的非均质性的刻画。从本质上讲,储层地质建模是从三维的角度对储层进行定量的研究,其核心是对井间储层进行多学科综合一体化、三维定量化及可视化的预测。目前储层建模技术中较为常用的几种建模方法有确定性建模及随机建模。随机建模是目前储层建模技术的突出发展方向,是根据地质适用性的不同而建立的不同模型。它是反映储层地质特征三维变化与分布的数字化模型。这个模型可以从三维空间上定量的表征油藏的非均质性,有利于油田勘探开发工作者进行合理的油藏评价及开发管理;可以用于油藏评价、储量计算、开发可行性评价,还可以优化油田的开发方案。在开发的中后期可以预测剩余油的分布,优化注水开发调整及三次采油方案;在储量计算中,利用储层建模可以更精确的计算油气储量,比常规的计算方法更准确;有利于三维油藏数值模拟,粗化的三维储层地质模型可以直接作为油藏数值模拟的输入。储层地质建模属于地质、数学与计算机等多学科结合的学科方向。建模内涵包括两大方面,其一为储层地质特征的计算机图形显示,属于计算机图形学的范畴,这一学科的发展已基本满足三维地质建模的图形显示需要,如储层格架、储层相与岩石物理参数分布的三维图形显示(目前已有的商业软件均可达到这一目的);其二为井间储层特征的预测,即应用已有信息预测储层特征的三维分布,这就要求相应的建模方法,它决定着所建立的模型是否符合地下地质实际,亦即建模精度。\n随机模拟方法的比较Petrel步骤数据加载、地层对比、断层建模、Pillar网格化、分层、相建模、岩石物性建模、体积计算、绘图、井位设计。储层建模主要包括哪几步数据准备、构造建模、储层相建模、储层参数建模、裂缝建模、油藏模型粗化。提高不确定性的对策提高地震的识别与预测精度(利用绕射波分离技术凸显了裂缝反射信息,提高了不整合面附近及内幕小规模缝洞体的识别、不同的边缘检测技术综合反映洞体特征,提高了缝洞识别的可靠性),加强地质成因背景研究,将现在的地质现象与古代地下形成的地质现象结合起来研究。对于不同的建模方法提出不同的优化对策建模方法减少不确定性对策确定性建模划分不同储层的平面,纵向分布,细分单元分别建模基于目标建模方法综合地震、地质成果,建立不同概率\n目标体几何形状参数高斯、指示建模方法不同类型约束体,采用不同变差函数及变程截断高斯模拟根据沉积特征不同,细化模拟单元,优化截断值分形模拟加强不同裂缝分形特征研究,优选分形计算方法多点地质统计学建立多套训练图像,确定不同沉积相的几何形状及空间接触关系储层随机建模的发展前景?(趋势、展望)答案1储层随机建模虽然经过不断完善,不断推陈出新,然而应该看到,地质现象是非常复杂的,储层随机建模在许多方面仍然需要努力,以满足油田生产开发的需求。3.1 目标之间相互影响与函数的确定目标之间相互影响具有成因上的意义。对于河道沉积,先期沉积的河道影响后期河道的分布。一般来说,先期沉积河道区由于地形的变化往往成为后期河道沉积时的背景相区。而同期沉积河道之间与沉积时构造、地形、坡度、物源等密切相关。仅考虑地质体之间的距离过于简化。此外对于不同目标体之间的影响考虑不够。例如,对于河流沉积体系,其沉积具有成因层次关系。河道规模决定着堤岸、决口扇等沉积微相的规模、分布等。对河流系统的建模应该考虑这些因素。而基于目标的示性点过程由于是分目标的模拟,很难考虑到目标间这种成因关系。如何在模拟中考虑目标之间的相互影响,并用数学模型来表征应该是储层建模以后研究的一个重要方向。3.2 获取反应实际储层结构特征的参数随机建模需要输入大量参数。在基于目标的建模中,需要输入目标的几何形态参数,以及目标相互之间影响参数;在两点统计学中,需要输入变差函数特征参数;在多点地质统计学中,需要输入反映储层结构特征的训练图像。这些参数的获取需要地质家仔细分析,其获取相当的困难。在基于目标的建模中,目标的几何形态参数化往往难以进行,因为地下储层形态很难用简单的长宽高来表述,甚至难以用数学函数来反映。在两点统计学中,变差函数仅反映了两点相关关系,其准确推断和拟合是模拟的基础。在多点统计学中,训练图象决定着多点概率的求取,不同的训练图像将会产生不同的模拟结果。如何获取反映地下储层结构特征的训练图像一直是研究的热点和难点。3.3 先验概率的求取\n在储层随机建模中,先验概率的获得往往被忽视。先验概率也是影响模型不确定性的重要因素。在勘探阶段,先验概率的提取相当困难,这是因为此时数据量过少,不足以推断出目标参数准确分布,导致模拟结果带有不确定性。在开发阶段,数据量增加,使得先验概率的推断成为可能。尽管如此,这种先验概率的获得仍然依赖于人的主观思考,因而其中必然存在不确定性。因此对先验概率的求取也应该引起相当重视。3.4 随机模拟结果评价对随机模拟结果的评价一直受到储层建模家关注。为了对随机模拟结果进行合理评价,不同学者给出了不同的评判标准。例如通过统计多个实现上每个网格点目标出现的概率来获取最优的模拟结果;通过抽稀检验评价模拟结果;通过与实际储层展布模式对比评价模拟结果等等。由于随机建模结果将会输入到数值模拟中,因此利用数值模拟结果进行检验将是对随机模拟结果评价的一个方向。答案2储层随机建模技术用于研究储层岩相、裂缝、孔隙、渗透率、流体饱和度的分布规律并提供关于数据空白区的一系列的随机模拟数据。 其发展一方面体现在建模方法本身的研究进展上,另一方面体现在其使用资料及适用领域方面的拓展。有关随机建模方法的文献近年来在一些会议和杂志上大量出现。这些文献对诸如马尔可夫随机模拟、河道分布模拟、依据地震数据用神经网络法进行岩相模拟、分形模拟、序贯高斯模拟和截断高斯模拟以及概率场模拟之间的理论联系、基于目标模拟和基于象元模拟方法的差别等等问题进行了讨论。 根据该方面所发表的文献看,随机建模技术目前比较前沿的领域是马尔可夫、半马尔可夫域模拟,分形模拟在裂缝研究中的应用,示性点过程模拟中地质知识的应用,不同建模方法的耦合等问题。而且,由于研究的深入,过去储层表征、随机建模领域主要利用井资料分析相带空间展布及物性空间特征的基本格局正在被突破。地震资料在储层随机建模中的应用越来越多,如岩相建模时地震速度的应用,模拟退火算法中地震资料和露头及井资料的结合等。由于这些进展,随机建模的思路与方法也开始在地震正演、反演中得到应用。 储层随机建模技术已经成为储层精细描述、预测及勘探开发风险评价的有效手段并在不断发展之中。由于不同沉积模型研究尺度大小不同,较大尺度沉积模型的\n研究往往对较小尺度规模的模型研究产生制约,因此,对研究区比例尺模型、相关概念模型及相关确定性储层建模技术的熟练掌握程度,往往与储层随机建模的有效与否有着重要关系,不同沉积模型之间的结合性研究会有力地促进储层随机建模方法研究以及随机建模应用领域的拓展。】储层建模的发展前景?(趋势、展望)鉴于目前储层建模存在的问题,期望在下述方面作进一步的研究,以提高建模方法的地质适用性,使地质模型更加逼近地质实际。3.1建模算法的改进前已述及,目前已有的储层建模算法尚存在一定的问题。以储层构型建模为例,目前的建模方法尚难于建立真正意义上的三维储层构型模型。对于基于目标的方法,今后算法的改进主要在以下几个方面:(1)复杂地质体的建模问题,如将储层构型分析中的侧积体作为目标体的随机建模;(2)获取先验地质知识并有效地整合到建模过程中;(3)基于过程的模拟如何实现井数据条件化等。针对多点统计建模,可以考虑从以下方面改进:(1)建立不同的训练图像以反映不同的非均质性,解决如河道的规模变化、形态变化等非平稳现象;(2)目标体连续性的改进,以产生更加连续的目标体;(3)三维模拟中数据事件及三维训练图像的建立;(4)综合多学科信息以及物性建模等方面。另外,裂缝性及缝洞性储层的建模算法仍很不完善,亦需大力改进。3.2原型模型的丰富通过露头、现代沉积及开发成熟油田的密井网区建立储层地质知识库,可为储层建模提供必要的地质统计特征参数。国内外学者对此作了不少的工作。然而,已有的定量地质知识库尚需进一步完善,以满足精细储层地质建模的需要。地质知识库不仅要求有单一成因单元的定量几何形态,而且要求有各成因单元的定量组合模式;另外,针对同一沉积类型,应建立其不同演化阶段的储层构型过程响应定量模式。3.3地震信息的整合在储层建模过程中如何充分应用地震属性是目前面临的主要挑战之一。地震资料具有其它资料难于比拟的井间横向信息,但其不足是垂向分辨率低与多解性强。已有建模方法虽然考虑了地震信息的整合,但尚有很多问题需要解决。\n在继续提高地震垂向分辨率的前提下,约束地震资料的多解性就成为提高储层预测与建模精度的关键。一是应加强地震正演模拟,进一步研究不同类型储层定量模式的地震响应;二是应进一步发展相控储层预测方法,以提高储层预测的精度;三是应进一步研究整合地震属性特别是多属性的储层建模算法。另外,由于地震资料为时间域信息,因此加强速度场研究,提高时—深转换精度亦是应用地震资料进行精细地质建模的关键。3.4地质约束为了建立尽量符合地质实际的储层模型,在建模过程中应尽量进行地质约束,如等时约束建模、成因控制建模、应用目标区多学科信息或原型模型确定统计特征参数建模、应用确定性信息限定随机模拟过程等地质约束原则。除此之外,在建模过程中应特别重视层次分析与模式拟合。沉积地质体具有层次性。因此,应分别按照不同级次的构型进行建模,如分别按微相组合、单一微相、微相内部单元等进行建模。对于不同级次的构型,输入反映各自地质特征的不同的建模参数,这样可使所建模型能更客观地反映地质实际。模式拟合建模主要是指在各层次的建模过程中,分别依据不同级次的定量模式,对储层的空间分布和物性特征进行合理的井间预测。层次分析与模式拟合应贯穿于储层建模的全过程。查看更多