- 2022-08-13 发布 |
- 37.5 KB |
- 40页


申明敬告: 本站不保证该用户上传的文档完整性,不预览、不比对内容而直接下载产生的反悔问题本站不予受理。
文档介绍
医学统计学作业
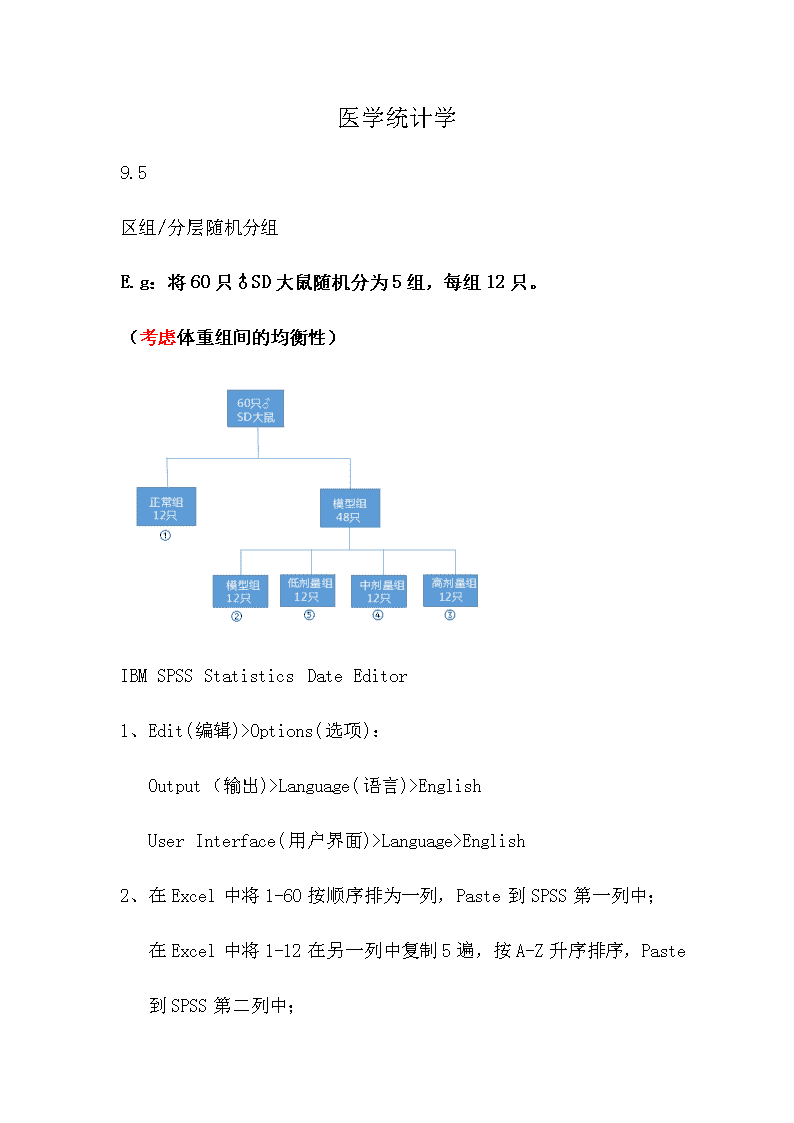
医学统计学9.5区组/分层随机分组E.g:将60只♂SD大鼠随机分为5组,每组12只。(考虑体重组间的均衡性)IBMSPSSStatisticsDateEditor1、Edit(编辑)>Options(选项):Output(输出)>Language(语言)>EnglishUserInterface(用户界面)>Language>English2、在Excel中将1-60按顺序排为一列,Paste到SPSS第一列中;在Excel中将1-12在另一列中复制5遍,按A-Z升序排序,Paste到SPSS第二列中;\n2、从DateView切换到VariableView,Name1、2分别为NO、Block,Decimals为0;3、Transform(转换)>RandomNumberGenerators(随机数字生成器):ActiveGeneratorInitialization(活动生成器初始化)>SetStartingPoint(设置起点)>FixedValue>Value:>OK;4、Transform>ComputeVariable(计算变量):TargetVariable:rFunctiongroup(函数组):RandomNumbersFunctionsandSpecialVariables:Rv.UiformNumericExpression:Rv.UNIFORM(0,1)>OK6、Transform>RankCases:rVariable>OK;7、Transform>RankCases:Rankofr[Rr]VaribleBlockBy8、将Rr的Decimals(小数)变为0将RRr的Decimals变为0将RRr的Name变为Group\nGroup:Values>ValueLabelsValue:1Label:正常组AddValue:2Label:模型组AddValue:3Label:高剂量组AddValue:4Label:中剂量组AddValue:5Label:低剂量组Add7、View>ValueLables10、File>SaveFile>Saveas:李静区组随机分配.xlsExcel97through2003(*.xls)\n9.12完全随机分组E.g:将60只♂SD大鼠随机分为5组,每组12只。(不考虑体重组间的均衡性)1、在Excel中将1-60按顺序排为一列,Paste到SPSS第一列中,Name:NODecimals:0;2、Transform(转换)>RandomNumberGenerators(随机数字生成器):\nActiveGeneratorInitialization>SetStartingPoint>FixedValue>Value:>OK;3、Transform>ComputeVariable(计算变量):TargetVariable:rFunctiongroup:RandomNumbersFunctionsandSpecialVariables:Rv.UiformNumericExpression:Rv.UNIFORM(0,1)>OKr:Decimals:44、Transform>RankCases:rVariable>OKRr:Decimals:05、Transform>RecodeintoDifferentvariables(重新编码为不同变量)Rankofr[Rr]InputVariable--OutputVariableOutputVariable:Name:GroupChange6、OldandNewValuesOldValue:Range:1to12\nNewValue:Value:1AddOldValue:Range:13to24NewValue:Value:2AddOldValue:Range:25to36NewValue:Value:3AddOldValue:Range:37to48NewValue:Value:4AddOldValue:Range:49to60NewValue:Value:5AddContinue>OKDecimals:0\n9.12E.g:某地2009年随机抽取102名成年男子测量其血红蛋白含量(g/L)判断计量资料是否服从正态分布?1、Analyze>DescriptiveStatistics>Explore:血红蛋白DependentList\nPlots>Normalityplotswithtests>Continue>OK1、Output:TestsofNormality样本量>2000,看左侧(大样本)样本量<2000,看右侧(小样本)Sig>0.05,服从正太分布绘制频数分布图/直方图(Histogram)1、Graphs>LegacyDialogs>Histogram:血红蛋白Variable>OK2、Output:原始图3、ChartEditorPropertiesChartSize:Height:Width=5:7取消勾选MaintainaspectratioBinning:Custom:NumberofintervalsLabel&Ticks:Style:Inside\nFill&Border:ColorFillPatternTextStyle:Style:Bold4、经Word、画图(或PS)处理(处理前)(处理后)\n9.19常用统计图绘制一、直条图(bargraph)12-1(单式直条图)1、Graphs>LegacyDialogs>Bar>Simple;2、BarRepresent:Otherstatistics(e.g.,mean)疗效Variable肺炎种类CategoryAxis3、BarOptions:Width:Bars:50%直条宽度和间隙宽度等宽或者间隙是直条宽度的1/24、显示数值ShowDateLabels:Displayed:PercentNotDisplayed:疗效、肺炎种类\n12-2(双直条图)Graphs>LegacyDialogs>Bar>Clustered二、百分条图(percentbar)12-31、加权平均Date>WeightCases:Weightcasesby人数FrequencyVariable2、Graphs>LegacyDialogs>PieDateinChartAre:Summariesforgroupsofcases3、SlicesRepresent:Sumofvariable疗效Variable\n人数DefineSlicesby4、显示构成比例(见上)5、从大到小顺时针:Categories:Order6、ExplodeSlice三、直方图(histogram)12-71、Graphs>LegacyDialogs>Histogram:血清铜含量Variable2、Binning:Custom:Numberofintervals:8\n四、线图(linegraph)12-51、Graphs>LegacyDialogs>Line>Multiple2、LinesRepresent:OtherStatistics(e.g.,mean)死亡率Variable错误放置变量绘制的图:\n更正后:1、原点坐标变为0Properties:Scale>Lowermargin(%):0Categories>Lowermargin(%):0\n1、半对数线图:Scale>Logarithmic五、人口金字塔图1、Graphs>LegacyDialogs>PopulationPyramid2、Counts:Getcountsfromvariable人口数/构成Variable\n年龄别ShowDistributionover性别Splitby1、去间隙BarOptions:Bar:100%\n第二章计量资料的统计描述一、频数分布表、频数分布图某地102名成年男性血红蛋白含量(g/L)绘制频数分布表:1、计算极差;2、确定组数、组距及组段(一般在10—15组);3、汇总各组段的频数绘制频数分布图:频数分布表和频数分布图的用途:1、描述频数分布的类型;类型:\n1、展示频数分布的特征;特征:集中趋势和离散趋势2、异常值的识别;3、有利于进一步对资料进行统计描述与分析;二、计量资料的统计指标集中趋势的描述:平均数(average)1、算数平均数/均数(mean)X:样本均数μ:总体均数用途:对称分布,即正态分布或近正态分布2、几何均数(G)用途:等比、对数正太分布,例如抗体滴度3、中位数(M)和百分位数(Px)中位数:特殊的百分位数,即第50位百分位数P50百分位数:估计医学参考值范围用途:任意、偏态资料、开口资料\n3、众数(mode)离散趋势的描述:1、极差(全距)2、四分位数间距(Q)是上四分位数Qu(P75)与下四分位数Ql(P25)之差中间50%观察值的极差3、方差(variance)反映一组数据的平均离散水平样本方差:S2总体方差:σ24、标准差样本标准差:S总体标准差:σ5、变异系数/离散系数(CV)CV=标准差/均数集中趋势离散趋势正态分布均数方差偏态分布中位数四分位数间距\n三、正态分布正态分布(高斯分布):两端低,中间高正态分布的概率密度函数正态分布表示:N(μ,σ2)μ:位置参数(μ越大,右移)σ:形态参数(σ越小,离散度越低,越尖)标准正太分布的概率密度函数标准正太分布表示:N(0,1)正态分布曲线下面积规律:1、区间在(μ-1.96σ,μ+1.96σ)内的面积或概率为0.95;2、区间在(μ-2.58σ,μ+2.58σ)内的面积或概率为0.99;正态分布的应用:制定医学参考值范围医学参考值范围是包括绝大多数正常人(不一定完全健康)医学参考值范围的估计:百分位数法:95%双侧:P2.5—P97.5单侧:下限P5,上限P95\n四、探索性描述性分析(确定分布类型)1、Analyze>DescriptiveStatistics>Descriptives血红蛋白VariableDescriptiveStatisticsNMinimumMaximumMeanStd.Deviation血红蛋白102103173136.8713.027ValidN(listwise)1022、Analyze>DescriptiveStatistics>Explore血红蛋白DependentListCaseProcessingSummaryCasesValidMissingTotalNPercentNPercentNPercent血红蛋白102100.0%00.0%102100.0%\nDescriptivesStatisticStd.Error血红蛋白Mean136.871.29095%ConfidenceIntervalforMeanLowerBound134.31UpperBound139.435%TrimmedMean136.91Median137.50Variance169.696Std.Deviation13.027Minimum103Maximum173Range70InterquartileRange17Skewness-.066.239Kurtosis-.101.474\n血红蛋白Stem-and-LeafPlotFrequencyStem&Leaf1.00Extremes(=<103)1.0010.92.0011.137.0011.7.0012.10.0012.15.0013.333414.0013.89915.0014.334412.0014.910.0015.4.0015.56783.0016.0121.00Extremes(>=173)Stemwidth:10Eachleaf:1case(s)横线位于近似中间即服从正态分布血红蛋白Stem-and-LeafPlotFrequencyStem&Leaf1.00Extremes(=<103)1.0010.92.0011.137.0011.7.0012.10.0012.15.0013.333414.0013.89915.0014.334412.0014.910.0015.4.0015.56783.0016.0121.00Extremes(>=173)Stemwidth:10Eachleaf:1case(s)\n五、百分位数1、Analyze>DescriptiveStatistics>Frequency(频数)2、血红蛋白VariableStatistics:PercentileValues:QuartilesCutpointsforPercentile√:5AddStatistics血红蛋白NValid102Missing0Percentiles5115.15\n六、几何均数(了解)1、Analyze>Reports>CasesSummaries2、血红蛋白VariableStatisticsGeometricMeanCellStatisticsCaseProcessingSummaryaCasesIncludedExcludedTotalNPercentNPercentNPercent血红蛋白100100.0%00.0%100100.0%a.Limitedtofirst100cases.七、医学参考值范围百分位书法(双侧)P2.5和P97.5Statistics血红蛋白NValid102Missing0\nPercentiles2.5110.1597.5161.43第三章总体均数的估计和假设检验一、抽样误差与标准误抽样误差:X1-=?X2-,Xi-=?μ标准误(σx-):样本均数的标准差σx-=σ/√n通常总体标准差σ未知,用样本标准差S代替Sx-=S/√n\n标准误越小,抽样误差越小注:若总体服从正态分布,样本均数X-一定服从正态分布;若总体不服从正态分布,当样本均数X-为大样本时服从正态分布;一、样本均数的抽样分布—t分布总体服从正态分布,样本均数X-一定服从正态分布即N(μ,σ2),N(μ,σx-2)Z变换:Z=X-~N(0,1)总体标准差σ未知,用样本标准差S代替t变换:t=X-~t(υ)t分布的特征:1、以0为中心;2、υ越小,t值越离散;3、υ无穷大,t分布为标准正态分布用途:小样本计量资料统计推断(总体均数的区间估计和t检验)三、总体均数的估计参数估计:根据样本数据,计算样本统计量,估计总体参数方法:点估计、区间估计点估计:样本均数X-作为总体均数μ\n区间估计:按预先给定的概率估计总体参数可能存在的范围,也叫可信区间(CI)可信度:1-α95%(或99%)的可信区间(可信下限,可信上限)可信区间两要素:准确度、精确度准确度:越接近1,准确度越高;精确度:可信区间范围越小,精确度越高。计算:总体均数95%的可信区间三、假设检验(9’)步骤:1、建立假设,确定检验水准;Ho:μ1=μ2(即假设两总体均数相等,样本均数的差别仅由抽样误差所致)H1:μ1><μ2α=0.052、选择检验方法,计算检验统计量;\nt=P=1、做出统计推断结论。P<=α,拒绝Ho,接受H1;(差异有统计学意义)P>α,接受Ho,拒绝H1。(差异无统计学意义)五、正态性检验SPSS操作:Shapiro-Wilk/W检验:小样本资料的正态性检验(8<=n<50);Kolmogorov-Smirnov/D检验:大样本资料的正态性检验(n>=50)。第四章t检验t检验:首先要进行正态检验(计量资料都需要)一、单样本t检验(One-SampleTTest)条件:总体资料服从正态分布原理:从正态总体资料,随机抽取样本含量n,算得均数、标准差,判断其总体均数μ是否与某个已知总体均数μo相同。li301判断铅作业工人血红蛋白含量是否低于正常成年男性?1、正态性检验:\nAnalyse>DescriptiveStatistics>Explore血红蛋白DependentList(因变量列表)Plots(绘制):NormalityPlotswithtests(带检验的正态图)正态性检验结果TestsofNormalityKolmogorov-SmirnovaShapiro-WilkStatisticdfSig.StatisticdfSig.血红蛋白.036102.200*.997102.999*.Thisisalowerboundofthetruesignificance.a.LillieforsSignificanceCorrection(1)建立假设,确定检验水准;Ho:服从正态分布H1:不服从正态分布α=0.05(2)选择检验方法,计算检验统计量;n>50,采用Kolmogorov-Smirnov检验P=0.2>0.05(3)作出统计推断。\n按α=0.05检验水准,接受Ho,拒绝H1,所以服从正态分布。2、单样本t检验(1)建立假设,确定检验水准;Ho:铅作业工人血红蛋白含量等于正常成年男性H1:铅作业工人血红蛋白含量低于正常成年男性α=0.05(2)选择检验方法,计算检验统计量;Analyse>CompareMeans>One-SampleTTest血红蛋白TestVariablesTestValue:140One-SampleStatisticsNMeanStd.DeviationStd.ErrorMean血红蛋白102136.8713.0271.290单个样本统计量N均值标准差均值的标准误血红蛋白102136.8713.0271.290\nOne-SampleTestTestValue=140tdfSig.(2-tailed)MeanDifference95%ConfidenceIntervaloftheDifferenceLowerUpper血红蛋白-2.425101.017-3.127-5.69-.57单个样本检验检验值=140tdfSig.(双侧)均值差值差分的95%置信区间下限上限血红蛋白-2.425101.017-3.127-5.69-.57因为总体资料服从正态分布,所以选择t检验t=-2.425P=0.017<0.05(3)做出统计推断。按α=0.05的检验水准,拒绝Ho,接受H1,即铅作业工人血红蛋白含量低于正常成年男性。二、两独立样本t检验(TwoDependentSimplettest)条件:1、两样本来自同分布的总体,即同质性;2、样本个体测量值相互独立;3、两个样本所代表的总体服从正态分布;\n4、总体方差相等,即方差齐性;li303难产婴儿体重不同于顺产婴儿体重(12.5’)顺产婴儿组:X1-=3.20kg,S1=0.40kg,总体均数μ1;难产婴儿组:X2-=3.52kg,S2=0.51kg,总体均数μ2。问:μ1><μ2?1、正态性检验(1)建立假设,确定检验水准;Ho:婴儿出生体重服从正态分布H1:婴儿出生体重不服从正态分布α=0.05(2)确定检验方法,计算检验统计量Analyse>DescriptiveStatistics>Explore体重DependentList(因变量列表)婴儿分组FactorList(因子列表)Plots>NormalityPlotswithtestsUntransformed(方差齐性检验)\nTestsofNormality婴儿分组Kolmogorov-SmirnovaShapiro-WilkStatisticdfSig.StatisticdfSig.体重顺产组.15020.200*.96620.675难产组.10220.200*.96520.654*.Thisisalowerboundofthetruesignificance.a.LillieforsSignificanceCorrectionTestofHomogeneityofVarianceLeveneStatisticdf1df2Sig.体重BasedonMean2.175138.148BasedonMedian2.125138.153BasedonMedianandwithadjusteddf2.125137.946.153Basedontrimmedmean2.101138.155两组n<50,选择检验Shapiro-Wilk两组P>0.05(3)做出统计推断。按α=0.05的检验水准,接受Ho,拒绝H1,即婴儿出生体重服从正态分布。2、两独立样本t检验\n(1)建立假设,确定检验水准;Ho:难产婴儿体重=顺产婴儿体重H1:难产婴儿体重><顺产婴儿体重α=0.05(2)确定检验方法,计算检验统计量;因为总体资料服从正态分布,所以选择t检验。Analyse>CompareMeans>Dependent-Simplettest体重TestVariables(检验变量)婴儿分组GroupingVariables(分组变量)DefineGroups:Group1:1Group2:2方差齐性检验(见上)服从正态分布,方差不齐,看下一行t检验;服从正态分布,方差齐,看上一行t检验;\nIndependentSamplesTestLevene'sTestforEqualityofVariancest-testforEqualityofMeansFSig.tdfSig.(2-tailed)MeanDifferenceStd.ErrorDifference95%ConfidenceIntervaloftheDifferenceLowerUpper体重Equalvariancesassumed2.175.148-2.21038.033-.32000.14477-.61307-.02693Equalvariancesnotassumed-2.21035.982.034-.32000.14477-.61361-.02639t=-2.210P=0.034<0.05(3)做出统计推断。按α=0.05的检验水准,拒绝Ho,接受H1,即难产婴儿体重和顺产婴儿体重不等。三、两独立样本的方差齐性检验F检验和Levene检验\n1、F检验:正态总体F=S大2/S小22、Levene检验:正态总体和非正态总体Spss在进行两独立样本t检验时自带基于均数(正态资料)的Levene法的方差齐性检验。第五章方差分析一、方差分析的基本思想\n\n\n查看更多