- 2022-08-13 发布 |
- 37.5 KB |
- 19页

申明敬告: 本站不保证该用户上传的文档完整性,不预览、不比对内容而直接下载产生的反悔问题本站不予受理。
文档介绍
统计学上机实习
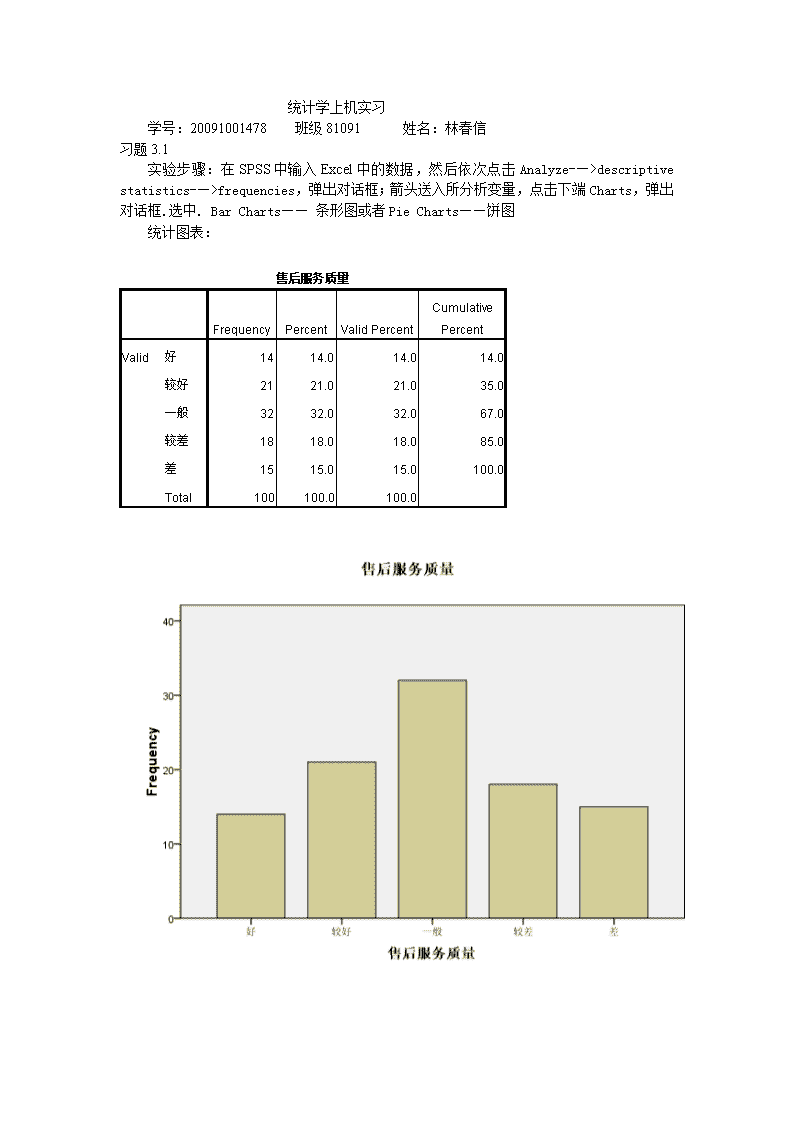
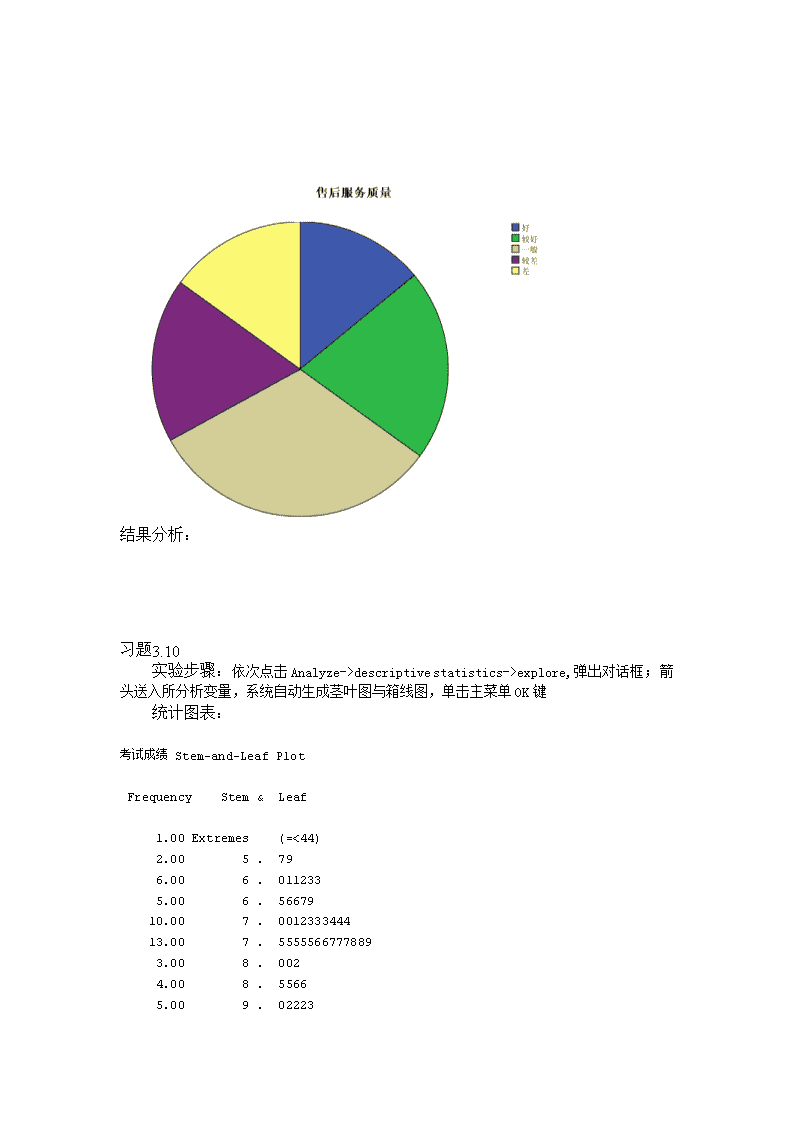
统计学上机实习学号:20091001478班级81091姓名:林春信习题3.1实验步骤:在SPSS中输入Excel中的数据,然后依次点击Analyze-—>descriptivestatistics-—>frequencies,弹出对话框;箭头送入所分析变量,点击下端Charts,弹出对话框.选中.BarCharts——条形图或者PieCharts——饼图统计图表:售后服务质量FrequencyPercentValidPercentCumulativePercentValid好1414.014.014.0较好2121.021.035.0一般3232.032.067.0较差1818.018.085.0差1515.015.0100.0Total100100.0100.0\n结果分析:习题3.10实验步骤:依次点击Analyze->descriptivestatistics->explore,弹出对话框;箭头送入所分析变量,系统自动生成茎叶图与箱线图,单击主菜单OK键统计图表:考试成绩 Stem-and-Leaf Plot Frequency Stem & Leaf 1.00 Extremes (=<44) 2.00 5 . 79 6.00 6 . 011233 5.00 6 . 56679 10.00 7 . 0012333444 13.00 7 . 5555566777889 3.00 8 . 002 4.00 8 . 5566 5.00 9 . 02223\n 1.00 9 . 6 Stem width: 10 Each leaf: 1 case(s)结果分析:习题3.14实验步骤:先把第一产业,第二产业,第三产业的Type中的String改为Numeric,然后依次点击Graphs->Legacydiaglos->Line,在弹出的对话框中选择Multiple和Summariesofseparatevariables,然后点击Define。在弹出的对话框把第一产业,第二产业,第三产业和国内生产总值放入LinesRepresent,把年份放入CategoryAxis。最后点击OK统计图表:\n结果分析:习题电脑销量实验步骤:依次点击Graphs->Legacydiaglos->Histogram,然后把电脑销量放入variables,再点击OK统计图表:\n结果分析:根据顾客购买饮料的记录,编制频数分布表实验步骤:依次点击Analyze-—>descriptivestatistics-—>frequencies,弹出对话框,把顾客性别,饮料类型放入variables中,再点击OK统计图表:顾客性别FrequencyPercentValidPercentCumulativePercentValid男2244.044.044.0女2856.056.0100.0Total50100.0100.0饮料类型FrequencyPercentValidPercentCumulativePercentValid果汁612.012.012.0矿泉水1020.020.032.0绿茶1122.022.054.0\n其他816.016.070.0碳酸饮料1530.030.0100.0Total50100.0100.0结果分析:基本描述统计量计量分析实验步骤:依次点击Analyze-—>descriptivestatistics-—>descriptive,弹出对话框;统计图表:DescriptiveStatisticsNMinimumMaximumMeanStd.Deviation电脑销售量120141237184.5721.681ValidN(listwise)120结果分析:交叉分组下的频数分析:实验步骤:CaseProcessingSummaryCasesValidMissingTotalNPercentNPercentNPercent性别*买衣物首选因素30100.0%0.0%30100.0%性别*买衣物首选因素CrosstabulationCount买衣物首选因素Total价格款式品牌性别男65415女85215\nTotal1410630练习1:某年中国10省市人均国民收入(3577,2981,1148,1124,1080,1383,1628,4822,1696,1717),单位:元,试建立该组数据的95%置信区间。实验步骤:依次点击Analyze-—>DescriptiveStatistics-—>Explore;统计图表:Descriptives\nStatisticStd.Error省市人均国民收入Mean2115.60398.75695%ConfidenceIntervalforMeanLowerBound1213.55UpperBound3017.655%TrimmedMean2022.78Median1662.00Variance1.590E6Std.Deviation1.261E3Minimum1080Maximum4822Range3742InterquartileRange1988Skewness1.382.687Kurtosis1.0271.334分析结果:习题:现有一组样本观察值(10.01,10.02,10.02,9.9)。假设原假设µ=10,检验该H0是否正确实验步骤:点击Analyze->CompareMeans->OneSampleTtest,在弹出的对话框中将样本观察值作为检验变量,栏中填入10,最后点击OK统计图表:One-SampleTestTestValue=10tdfSig.(2-tailed)MeanDifference95%ConfidenceIntervaloftheDifferenceLowerUpper样本观察值-.4273.698-.01250-.1056.0806结果分析:教材p243页8.12\n实验步骤:选择AnalyzeàCompareMeansàIndepentdent-SamplesTTest统计图表:GroupStatistics方法NMeanStd.DeviationStd.ErrorMean工时甲方法1231.753.194.922乙方法1128.732.573.776IndependentSamplesTestLevene'sTestforEqualityofVariancest-testforEqualityofMeansFSig.tdfSig.(2-tailed)MeanDifferenceStd.ErrorDifference95%ConfidenceIntervaloftheDifferenceLowerUpper工时Equalvariancesassumed.348.5622.48421.0213.0231.217.4925.553Equalvariancesnotassumed2.50820.683.0213.0231.205.5145.531结果分析:随机选择了8名肥胖儿童试验一种减肥方案,减肥前后的体重如表6-6。根据实验结果,在5%的显著性水平下能否认为减肥方案有效? 表1一种减肥方案的试验数据减肥前4555544856536249减肥后4348504750475946实验步骤:把数据输入SPSS数据表,选择AnalyzeàCompareMeansà\nPaired-SampleTTest,在弹出的对话框中将两个变量作为一组数据选为分析变量,统计图表: PairedDifferencestdfSig.(2-tailed) Mean标准差均值标准误95%置信区间 VAR1-VAR24.0002.13809.755932.21255.78755.2927.001结果分析:根据本题的题意,将假设检验的零假设设为,备择假设设为。如果拒绝零假设则说明减肥方案有效。根据表检验的t统计量等于5.292,双侧检验的p-值为0.01,因此右侧检验的p-值为0.0005。在5%的显著性水平下显然应拒绝零假设,结论是减肥方案有效。 1、某工厂为检验不同包装商品的销售效果,随机抽取样本,问不同包装的商品销售是否有显著性差异?(α=0.05)相关资料表包装一包装二包装三779572869277808268889182实验步骤:单击AnalyzeàmpareMeansàOne-WayANOVA,在对话框中将变量“销量”选入DependentList框,将变量“包装”移入Factor栏。单击对话框中的“Options”按钮,在弹出的对话框中选中“Discriptive(描述统计)”、“Homogeneityofvariancetest(同方差检验”和“Meansplot(均值的图形)”复选框(图7-5)。单击主对话框中的“PostHoc(事后多重比较)”,选中“LSD(最小显著差异方法)”复选框。单击主对话框中的“OK”按钮,就可以得到相应的分析结果了。统计图表:ANOVA销量SumofSquaresdfMeanSquareFSig.BetweenGroups465.5002232.7507.389.013WithinGroups283.500931.500Total749.00011MultipleComparisons销量LSD\n(I)包装(J)包装MeanDifference(I-J)Std.ErrorSig.95%ConfidenceIntervalLowerBoundUpperBound包装一包装二-7.2503.969.101-16.231.73包装三8.0003.969.075-.9816.98包装二包装一7.2503.969.101-1.7316.23包装三15.250*3.969.0046.2724.23包装三包装一-8.0003.969.075-16.98.98包装二-15.250*3.969.004-24.23-6.27*.Themeandifferenceissignificantatthe0.05level.结果分析:2、某农科所试验在水溶液中种植西红柿,采用了三种施肥方式和四种不同的水温。三种施肥方式是:一开始就以全部可溶性肥料;每两个月给以50%溶液;每月给以25%溶液。水温分别为4度,10度,16度,20度。结果见下表-20。问施肥方式和水温对产量的影响各自是否显著?(α=0.05)。试验数据表水温施肥方式一次施肥分二次施肥分四次施肥冷(4度)201921凉(10度)161514温(16度)91011热(20度)876实验步骤:在SPSS中建立数据表以后,选择AnalyzeàGeneralLinearModelàUnivariate,在主对话框中将“销量”放入DependentVariable矩形框,将“水温”和“施肥方式”放入FixedFactor(s)矩形框中。在主对话框中点击Model按钮进入Model对话框,选择Custom,在效应下拉框中选择Maineffect,把“水温”和“施肥方式”变量选入右边的模型框中,单击Continue返回主对话框(图7-8)。其它选项采用默认值,单击主对话框中的“OK”按钮,可以得到无交互作用的双因素方差分析结果统计图表:Between-SubjectsFactorsValueLabelN\n施肥方式0一次施肥41分二次施肥42分四次施肥4水温0冷(4度)31凉(10度)32温(16度)33热(20度)3TestsofBetween-SubjectsEffectsDependentVariable:产量SourceTypeIIISumofSquaresdfMeanSquareFSig.CorrectedModel294.500a558.90047.120.000Intercept2028.00012028.0001.622E3.000施肥方式.5002.250.200.824水温294.000398.00078.400.000Error7.50061.250Total2330.00012CorrectedTotal302.00011a.RSquared=.975(AdjustedRSquared=.954)结果分析:练习:一民航客运量作为因变量(Y),以国民收入(X1),消费额(X2),铁路客运量(X3),民航航线里程(X4),来华旅游入境人数(X5)作为自变量,根据1984-1993年数据,研究我国民航客运量回归模型。要求:(1)制作散点图,对五个变量之间两两的相关关系作出初步观察和判断。(2)计算变量之间两两的相关系数并进行分析。(3)建立多元线性回归方程,并解释回归系数的实际意义。民航客运资料表客运量(万人)x1(亿元)x2(亿元)x3(万人)x4(万公里)x5(万人)231301018888149114.89180.92298335021958638916420.39343368825319220419.53570.25\n401394127999530021.82776.71445425830549992223.27792.43(1)实验步骤:Graphs->SimpleScatter/Dot->simplescatterplot,把两个变量分别放入X,Y列统计图表:正线性相关国民收入与消费额完全正线性相关国民收入与铁路客运量非相关\n国民收入与民航航线里程正线性相关国民收入与来华旅游入境人数正线性相关\n消费额与铁路客运量非线性相关消费额与民航航行里程正线性相关\n(2)实验步骤:操作步骤:Analyze->Correlate->Bivariate\n统计图表:Correlations客运量国民收入消费额铁路客运量民航航线里程来华旅游入境人数客运量PearsonCorrelation1.981**.976**.754*.972**.982**Sig.(2-tailed).000.000.012.000.000N101010101010国民收入PearsonCorrelation.981**1.998**.846**.974**.996**Sig.(2-tailed).000.000.002.000.000N101010101010消费额PearsonCorrelation.976**.998**1.867**.981**.998**Sig.(2-tailed).000.000.001.000.000N101010101010铁路客运量PearsonCorrelation.754*.846**.867**1.864**.848**Sig.(2-tailed).012.002.001.001.002N101010101010民航航线里程PearsonCorrelation.972**.974**.981**.864**1.980**Sig.(2-tailed).000.000.000.001.000N101010101010来华旅游入境人数PearsonCorrelation.982**.996**.998**.848**.980**1Sig.(2-tailed).000.000.000.002.000N101010101010**.Correlationissignificantatthe0.01level(2-tailed).*.Correlationissignificantatthe0.05level(2-tailed).结果分析:民航客运量与国民收入的相关系数为0.981,说明他们高度相关;民航客运量与消费额相关系数为0.976,说明他们高度相关;民航客运量与铁路客运量的相关系数为0.754,说明他们中度相关;民航\n客运量与民航航线里程的相关系数为0.972,说明他们高度相关,民航客运量与来华入境旅游人数相关系数为0.982,说明他们高度相关,国民收入与消费额相关系数为0.998,说明他们高度相关;国民收入铁路客运量的相关系数为0.846,说明他们高度相关;国民收入与民航航线里程的相关系数为0.974,说明他们高度相关,国民收入与来华入境旅游人数相关系数为0.996,说明他们高度相关。(3)实验步骤:Analyze-—>Regression-—>Linear,从左边把因变量客运量选入dependeat中,把自变量国民收入,消费额,铁路客运量,民航航线里程,来华旅游入境人数选入independeat中,最后点击ok统计图表:ModelSummarybModelRRSquareAdjustedRSquareStd.ErroroftheEstimate1.999a.998.99621.085a.Predictors:(Constant),来华旅游入境人数,铁路客运量,民航航线里程,国民收入,消费额b.DependentVariable:客运量ANOVAbModelSumofSquaresdfMeanSquareFSig.1Regression1075324.1155215064.823483.758.000aResidual1778.2854444.571Total1077102.4009a.Predictors:(Constant),来华旅游入境人数,铁路客运量,民航航线里程,国民收入,消费额b.DependentVariable:客运量CoefficientsaModelUnstandardizedCoefficientsStandardizedCoefficientstSig.BStd.ErrorBeta1(Constant)401.709144.7632.775.050国民收入.126.074.7741.692.166消费额-.071.191-.308-.372.729铁路客运量-.010.002-.327-4.560.010民航航线里程27.4365.258.5815.218.006来华旅游入境人数.094.190.226.496.646a.DependentVariable:客运量结果分析:多元线性回归方程为y=401.709+0.126(x1)-0.071(x2)-0.01(x3)+27.436(x4)+0.094(x5)。\n系数0.126表示在消费额,铁路客运量,民航航线里程,来华旅游入境人数不变情况下,国民收入每增加1亿元。客运量增加0.126万人系数-0.071表示在国民收入,铁路客运量,民航航线里程,来华旅游入境人数不变情况下,消费额每增加1亿元,客运量减少0.071万人系数-0.01表示在国民收入,消费额,民航航线里程,来华旅游入境人数不变情况下,铁路客运量每增加1万人,民航客运量减少0.01万人系数27.436表示国民收入,消费额,民航航线里程,来华旅游入境人数不变情况下,民航航线里程每增加1万公里,客运量增加27.436万人系数0.094表示国民收入,消费额,民航航线里程,民航航线里程不变情况下,来华旅游入境人数每增加1万人,客运量增加0.094万人查看更多